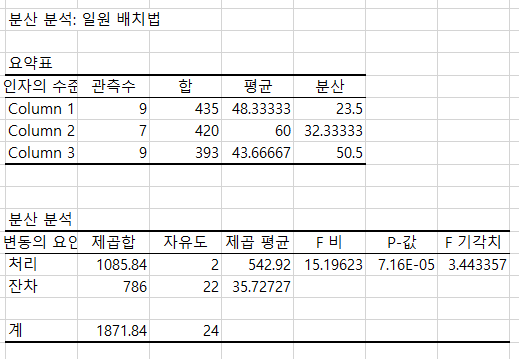
ANOVA 앞전에 올린 T-Test와 비슷한 ANOVA 분석을 알아봅시다! T-Test는 한가지의 요인에 대해 2개의 그룹을 비교하는 방법이였다고 하면, ANOVA는 한가지의 요인에 대해 3개 이상의 그룹을 비교하는 방법이예요. 1. 예제 경제학, 의학, 역사 학위를 갖고 있는 사람들의 급여이다. 이 3그룹의 평균은 같다고 할 수 있을까? H0: μ1 = μ2 = μ3 (세 그룹의 평균은 같다고 할 수 있다.) H1: 하나의 그룹이라도 평균이 다르다고 할 수 있다. 2. 엑셀로 ANOVA 분석하기 (1) 데이터탭 -> 데이터분석 -> 분산 분석 : 일원 배치법 (2) 입력범위 : 값 범위 / 유의 수준 : 0.05 (3) 결과값 해석하기 1) 요약표에서 보면 한눈에 합계/ 평균/ 분산을 확인할 수 있으며..